Finding a job with Python and Selenium
Finding a job can be a real grind. In this post, I’m going to show you how to automate a big chunk of that work using Python and Selenium. We’ll dive into how to find job boards that are easy to scrape, save that data, and then analyze it to pinpoint the jobs you’re most qualified for.
We’ll even explore how to use free AI tools like Ollama and LM Studio to filter jobs based on your skillset and extract keywords to make searching easier. And to top it all off, we’ll build a neat little web app with React and Flask to browse all the jobs we’ve scraped.
The Tools of the Trade
Python
I’m a big fan of Python for this kind of stuff. It’s simple, it’s effective, and it gets the job done. If you’re new to Python, you can learn how to get it set up here: Installing Python.
Selenium
While Python has some built-in tools for grabbing content from web pages, a lot of job boards use JavaScript to render their content. That’s where Selenium comes in. It lets us spin up a real browser session and control it with our code, so we can get to all that juicy, dynamically-rendered content.
SQLite
We’re going to be dealing with a lot of data, so Excel just isn’t going to cut it. I’ve got a single database table with about a week’s worth of job posts that’s already over 100MB. SQLite is perfect for this. It’s lightweight, and it’ll let us run the advanced queries we’ll need to analyze and sort through all the jobs we find.
Run the following command, and you should see the version of Python you have installed:
python --version
Python 3.11.7
Now we can install the libraries we’ll need
pip install requests beautifulsoup4 selenium webdriver-manager
Now I’ll create a new folder for my project. I name mine scraper but you can do whatever you want.
Job boards
Companies use many different sites to post their jobs. Some are easier to scrape than others and some have sophisticated automation detection(like indeed.com) and will make it very difficult to scrape. We’ve got to find a board that does not have this restriction, and also we need to keep in mind that many of the sites have rate limiters, so when we are collecting data we need to do it at a slow pace so we don’t overload the server. For the sake of this demo I’m going to pick the site softgarden.io. I search google with a query like: site:softgarden.io Senior Java Developer and I see this link:

Cool, I am one of the genders so this is great. Notice the subdomain serviceplan in the link https://serviceplan.softgarden.io/job/49387133/Senior-Full-Stack-Developer-all-genders/?l=en This is usually a url-friendly version of the companies name. We also see other domains such as https://inform-software.softgarden.io/. So, if you want to find if a company has jobs posted on softgarden.io you could query google with site:softgarden.io Novatec job and we might see something like this:
When we visit the link we see that particular job post. We want all of the posts by this particular company. To do this we’ll just knock everything off the url that comes after the domain and get a link like: Novatec Software Jobs
Cool, now we can see all of their job posts:
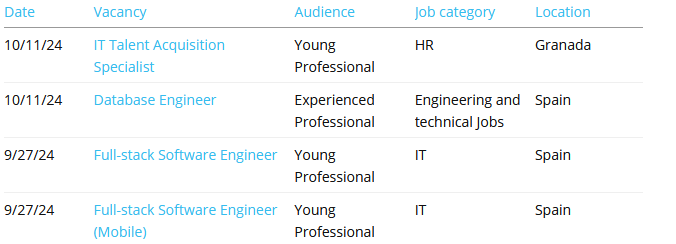
Let’s have a look at the page source and see what the HTML of these list items looks. We can right click on one of the Job links and select Inspect. This opens up the dev tools to the underlying code.
<div class="matchElement odd" style="undefined" id="job_id_49993923"></div>
We see each job is wrapped in a div that has an id attribute like job_id_49993923. This gives us a good target for scraping. Copy all the code from the View Source tab and save it to the file sample_board.html. We’ll use this file to work on instead of loading the page over and over as we work on our script.
Now let’s write some Python code to scrape the job details:
from bs4 import BeautifulSoup
# Read the HTML content from the file
with open('sample_board.html', 'r', encoding='utf-8') as file:
html_content = file.read()
# Parse the HTML content
soup = BeautifulSoup(html_content, 'html.parser')
# Find all divs with id starting with 'job_id_'
job_divs = soup.find_all('div', id=lambda x: x and x.startswith('job_id_'))
# Extract job details
jobs = []
for div in job_divs:
job_title = div.find('div', class_='matchValue title').text.strip()
job_link = div.find('a')['href']
job_location = div.find('div', class_='location-container').text.strip()
job_date = div.find('div', class_='matchValue date').text.strip()
base_url = "https://novatec-software.softgarden.io/"
full_link = base_url + job_link
jobs.append({'title': job_title, 'location': job_location, 'date': job_date, 'link': full_link})
# Print the extracted job details
for job in jobs:
print(job)
When you run the code you should see results like:
{'title': 'IT Talent Acquisition Specialist', 'location': 'Granada', 'date': '10/11/24', 'link': 'https://novatec-software.softgarden.io/../job/49993923/IT-Talent-Acquisition-Specialist-?jobDbPVId=160708533&l=en'}
{'title': 'Database Engineer', 'location': 'Spain', 'date': '10/11/24', 'link': 'https://novatec-software.softgarden.io/../job/49990373/Database-Engineer?jobDbPVId=160698573&l=en'}
{'title': 'Full-stack Software Engineer', 'location': 'Spain', 'date': '9/27/24', 'link': 'https://novatec-software.softgarden.io/../job/49472208/Full-stack-Software-Engineer?jobDbPVId=157409078&l=en'}
This is a great starting point. You can already collect a ton of job posts and filter them by title, but we’re just getting warmed up. In Part 2, we’ll get our database set up and figure out how to extract the full job descriptions from each post.
If you have any questions, feel free to shoot me an email at blakelinkd@gmail.com.